[논문]
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25, 1097–1105.
0. TL;DR
논문의 Key Points로, 이에 유념하며 읽는 것을 추천한다.
+) 꽤 오래된 논문이기 때문에 지금은 사용하지 않는 기법이나 와닿지 않는 표현(특히 스케일 측면에서)이 있을 수 있다. 시대적 배경을 잘 감안하며 읽기 바란다.
| 저자의 의도 | 당시(2012년) 기준으로 대규모 이미지 데이터셋을 분류 가능한 대형 모델을 구축하여 CV 도메인의 한계 돌파 |
| 핵심 요소 | - 8개라는 깊은 레이어 구조 - ReLU activation function - Dropout normalization - GPU parallelism을 통한 최적화 |
| 적용 가능성 | 사실 꽤 오래 전 논문이라 그대로 적용하기엔 다소 아쉬운 부분이 많다. 다만 AI 도메인에 익숙치 않은 독자라면 PyTorch 버전을 참고하며 어떤 식으로 기본 모듈이 짜이는지를 확인하면 큰 도움이 될 것 같다. |
| 참고하면 좋을 논문 | - VGGNet (2014): AlexNet에서 depth를 더 늘린 모델 - ResNet (2015): Skip connection 기법을 통해 depth를 더욱 늘린 모델 - Dropout (2012): 딥러닝 수업을 들은 적이 없다면 한번쯤 간단한 정리본으로라도 볼 것 |
1. Motivation
1-1. 기존 연구의 한계
1-1-1. Dataset 측면



NORB, CIFAR-10/100, Caltech-101/256 같은 기존 데이터셋은 규모가 n만 장 정도에 불과했다.
물론 이 정도 규모의 데이터셋만으로도 augmentation 등의 트릭을 사용하면 ML만으로도 simple object recognition task까지는 어느 정도 준수한 성능을 뽑을 수 있었다고 논문에서는 소개한다.
그러나 real world는 훨씬 복잡한 feature를 가지고 있기 때문에 더 큰 데이터셋이 필요하다는 사실은 어찌 보면 당연하게 느껴진다.
1-1-2. Computational cost 측면
CNN이라는 구조는 사실 AlexNet에서 처음 제시한 개념은 아니다.
이미 locality, stationarity라는 특성 덕에 그 이론적 우수성이 알려져 있었으나, 2012년 당시 하드웨어 스펙의 한계가 문제였다.
소규모 데이터셋에 대해서는 적용이 가능했을지 몰라도, 논문에서 제시한 ImageNet처럼 1500장이 넘어가는 대규모 데이터셋에 대해 CNN을 적용하기란 computational cost 측면에서 매우 challenging했던 것이다.
당시는 지금 같은 PyTorch, TensorFlow 같은 딥러닝 프레임워크도 없었을뿐더러 GPU에 텐서 코어도 없었다는 점을 고려해야 한다.
아무튼 이러한 환경 제약은 실제 구현을 어렵게 만드는 주요인이었다.
1-1-3. Overfitting 측면
무작정 model complexity를 키운다는 것은 overfitting 가능성을 충분히 고려하지 않은 naive한 선택이다.
Model complexity가 증가함에 따라 파라미터 수는 급증(이와 관련해서는 뒤에서 이론적 배경을 소개하겠다)하기 떄문에, training data에 과하게 최적화되는 overfitting이 발생할 수 있는 것이다.
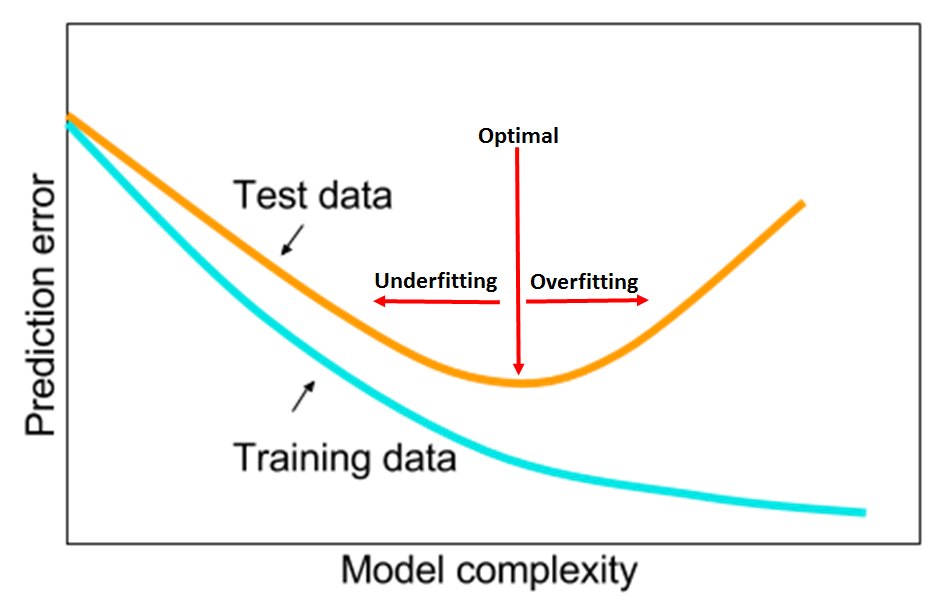
Overfitting의 가장 큰 문제점은 새로운 input data에 대해서 reasonable prediction을 할 수 있는 generalization 능력이 떨어진다는 것이다.
Dataset split 관점에서 생각해 보면, training dataset에 대해서는 prediction을 잘 수행하더라도 test dataset에 대해서는 prediction 성능이 떨어질 수 있다는 것이다.
따라서 대규모 데이터셋을 학습하기 위해 model complexity를 키우면서도 overfitting을 완화할 수 있는 조합이 필요했다.
1-2. 연구의 필요성
1-2-1. 데이터셋 크기와 learning capacity의 확장
Sec.1-1-1에서 언급했듯, 기존 소규모 데이터셋으로는 real world가 가진 variability에 대응하기 어려우며, 이는 곧 object recognition 성능의 upper bound 문제로 이어진다.
때문에 비교적 큰 규모의 데이터셋이 필요해지는 것인데, 단순히 데이터셋의 규모만을 키운다고 문제가 깔끔히 해결되지는 않는다.
그 이유는 각 모델 마다 갖고 있는 learning capacity의 한계 때문이다.
즉 선행연구들에서 제시한 모델들보다 depth와 breath가 커질 필요가 있었던 것이다.
1-2-2. CNN의 prior knowledge 활용
앞서 CNN은 그 우수성이 이미 이론적으로 입증되어 있다고 얘기했다.
CNN에는 통계적 특성을 기반으로 한 2가지 핵심 가정이 깔려있다.

그중 첫 번째가 Locality of pixel dependecies라는 특성으로, 이미지에서 특정 정보는 인접한 픽셀들끼리 모여 형성한다는 원리이다.
예를 들면 강아지 사진에서 '코(nose)'라는 정보는 코 주변의 픽셀들이 결정하는 것이지, 코에서 멀리 떨어진 눈이나 입에 있는 픽셀들과는 무관하다.
이 때문에 우리는 작은 사이즈의 커널(=필터)을 사용하는 것이다.

두 번째는 Stationarity of statistics로, 이미지의 한 부분에서 배운 특징은 다른 위치에서도 동일하게 사용할 수 있다는 원리이다.
어떤 이미지에서 사람의 입을 찾는다고 했을 때, 한 번 배운 뒤에는 이를 똑같이 활용할 수 있다는 것이다.
이러한 원리 덕에 Parameter sharing이 가능해지며, 이는 위치나 각도 등이 다른 '입'이라는 feature를 단 하나의 커널로 효율적으로 feature extraction할 수 있도록 만든다.
CNN의 이론적 특징에 관해서는 잘 정리된 블로그 글이 있으니, 더 자세히는 다루지 않겠다.
아무튼 정리를 해보자면, 데이터만으로는 해결되지 않는 복잡성을 극복하기 위해 이미지 feature에 더 적합한 CNN의 locality, stationarity를 prior knowledge로써 활용할 필요가 있다는 것이다.
2. Methods
2-1. 핵심 아이디어 요약
AlexNet의 핵심 methods를 정리해보면 다음과 같다.
- 기존 모델들보다 더 깊은 네트워크 구성으로 기존 SOTA인 SIFT+FVs 대비 더 낮은 top-1, top-5 rate를 달성했다.
- 2대의 GPU로 parallel operation을 적용해서 더 큰 규모의 CNN을 학습할 수 있도록 했다.
- ReLU activation function을 적용하여 기존 tanh 대비 약 6배 더 빠른 수렴 속도를 달성했다.
- Dropout, Data augmentation, Overlapping Pooling 기법을 함께 사용하여 overfitting을 효과적으로 억제했다.
2-2. 디테일
GPU parallelism의 디테일은 이번 리뷰의 ROI를 벗어난다고 생각하여 생략한다. LRN 기법 역시 최근에는 Batch Normalization의 등장으로 인해 사용되지 않기에 생략하려 한다.
2-2-1. Preprocessing: Mean Substraction
이 부분은 다른 파트에 비하면 크게 중요하지 않을지도 모른다. 하지만 이런 preprocessing이 학습 품질에 어떤 영향을 미치는지 간단히 짚고 넘어가려 한다.
이 연산은 데이터셋 전체의 이미지에 대해 pixel-wise mean 값을 구한 뒤, input 이미지로부터 해당 값을 pixel-wise substract하여 데이터를 0-centered로 만들어준다.
이런 과정이 중요한 이유는 gradient stability 때문이다.
Input 값이 모두 positive number인 경우, backpropagation에서 weight derivative가 모두 같은 부호를 갖게 된다(이 부분의 디테일은 backpropagation chain rule 식을 살펴보면 알 수 있다).

이러한 경우, weight update step에서 모든 weights는 다 같이 증가하거나 반대로 다 같이 감소해버리는 방향으로 업데이트되게 되는데, 우리가 찾는 optimal weight direction은 복합적으로, 어떤 weight는 증가하고 어떤 weight는 감소해야 할 수도 있다.
하지만 일괄 증가/감소만 발생하게 되면 위의 예시 이미지처럼 비효율적인 path로 업데이트되는 zig-zagging 현상이 발생하게 된다.
이는 수렴 속도를 저하시킬 뿐만 아니라 학습 안정성을 해칠 수 있다.
좀 더 직관적으로는, 조명/색상으로 인한 bias를 제거함으로써 모델이 이미지의 본질에 좀 더 집중하도록 하는 효과가 있다.
2-2-2. Architecture: ReLU + 8-Layer
- ReLU
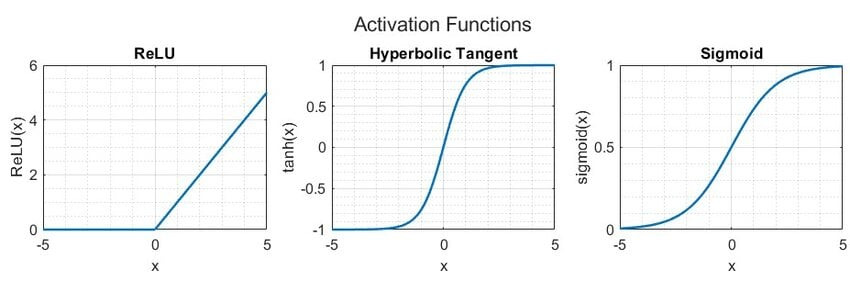
NN에서는 nonlinearity 주입을 위해 activation function을 노드마다 배치하곤 한다.
Nonlinearity가 필요한 이유로는, nonlinear function 근사를 할 수 있다는 점과 복잡한 feature까지 표현할 수 있게 된다는 정도가 있다.
더 자세히 얘기하면 universal approximation theorem 얘기도 해야하고, 이야기의 범위를 벗어나니 잘 정리된 글을 참고하자.
어쨌든 기존에 쓰이던 tanh 대비 ReLU에는 두 가지 장점이 있다.
$$\text{ReLU}(x)=\max(0,x)\,\,\,,\,\,\,\tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$$
첫 번째는 연산이 단순하고 빠르다는 것으로, 실제로 논문에서는 CIFAR-10 데이터셋 기준으로 비교했을 때 약 6배 가량의 속도 향상을 관찰했다고 한다.
Backpropagation 과정에서 activation function도 미분되어야 하기에, 두 함수 수식의 미분을 비교해 보면 쉽게 납득이 가능할 것이다.
두 번째는 논문에서 직접 언급되지 않지만 ReLU를 통해 gradient vanishing problem를 부분적으로 해결한다는 점이다.
그래프를 통해 tanh는 $|x|>2$에서 이미 뉴런이 saturate되어 gradient가 거의 0에 근접하는 것을 확인할 수 있다.
0에 가까운 gradient가 backpropagation 연산 결과 중에 하나라도 포함된다면 전체 gradient 값이 매우 작아져서 weight update가 제대로 일어나지 않게 된다.
반면 ReLU의 경우, $x>0$에서만큼은 이러한 문제를 부분적으로 해결하여 더 나은 weight update가 가능하다는 장점이 있다.
물론 $x\le0$에서는 ReLU 역시 똑같은 문제가 발생하기 때문에 요즘에는 이를 약간 개선한 Leaky ReLU를 주로 사용하곤 한다.
이 문제는 NN의 레이어가 많아질수록 더 심각해지기 때문에 AlexNet처럼 depth를 크게 가져가려는 모델에서는 효율적인 weight update를 위해 ReLU를 적용하는 것이 합리적인 선택이었다고 할 수 있다.
- 8-Layer

Embedding layer(가장 왼쪽)와 Pooling layer를 카운트하지 않고 learnable parameter를 포함하는 레이어들만 고려했을 때 8개의 레이어로 구성된다.
가장 오른쪽에 위치한 3개의 레이어가 FC(Fully-Connected) layer이며, 나머지 5개가 Convolution layer이다.

참고로 convolution layer는 kernel을 이미지 좌상단부터 우하단까지 sliding하며 convolution 연산을 수행한다.
보통 Kernel size라든가, Padding, Stride 등의 하이퍼파라미터를 설정하게 되는데 이에 대한 자세한 설명은 어렵지 않으니 생략하도록 하겠다.
우리가 convolution layer에서 파라미터로 간주하는 것이 바로 kernel에 할당된 weight이다.
그래서 kernel 사이즈에 따라, kernel 개수에 따라 각 convolution layer의 파라미터 개수가 결정된다.
우리는 여기에서 한 가지 중요한 내용을 정리하고 가야 한다.
바로 Convolution/FC/Pooling layer의 파라미터 개수, 메모리 사용량, FLOPs(1초당 floating point 연산 횟수로 클수록 좋음)이다.
(이는 AI 연구와 관련된 전공 면접에서 종종 튀어나오는 질문이므로 관련 전공자들은 필히 이해하고 넘어가는 것을 권장하나, 비전공자의 경우에는 넘어가도 된다.)
아래의 자료들은 임성훈 교수님의 DGIST CSE303 Introduction to Deep Learning 수업 자료를 발췌한 것이다.
메모리 사용량과 FLOPs는 크게 어렵지 않지만, 파라미터 개수는 처음에 좀 난해할 수 있기에 이에 대해서만 설명하고 넘어가겠다.
1) Convolution Layer

처음 보면 헷갈릴 만한 부분이 $C_{in}$과 $C_{out}$일 것이다.
사실 kernel은 단순히 2d array가 아니기 때문으로, 예를 들어 가장 첫 convolution layer에서는 이미지의 채널 수인 $C_{in}$(RGB인 경우 3채널)만큼의 kernel depth가 필요하다.
따라서 kernel의 부피만큼의 파라미터가 우선 필요하며, 다음 convolution layer의 채널 수인 $C_{out}$만큼의 kernel 개수가 필요하기 때문에 위와 같은 식이 나오는 것이다.
이때 보통 일반적으로 bias도 learnable bias를 사용하기 때문에 이를 고려한 최종 수식은 다음과 같다.
$$\text{# of params}=(K\times K\times C_{in}+1)\times C_{out}$$
2) FC Layer
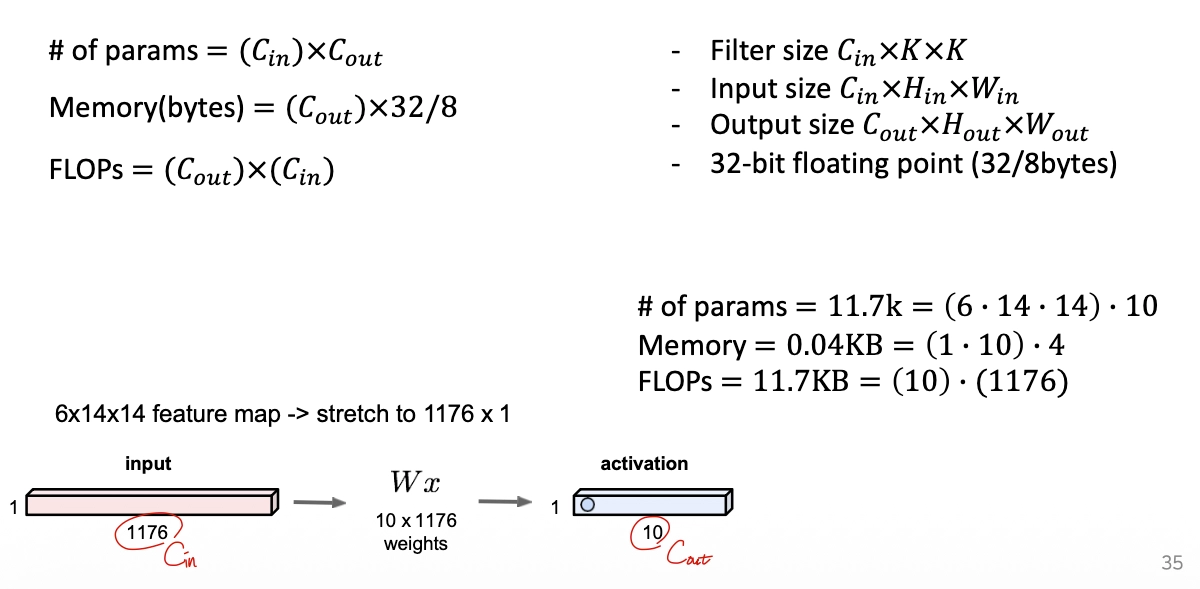
FC layer는 1d array이므로 계산이 복잡하지 않다.
하지만 FC layer 역시 일반적으로 learnable bias를 사용하므로 최종 수식은 아래와 같다.
$$\text{# of params}=(C_{in}+1)\times C_{out}$$
3) Pooling Layer

아키텍처 설명을 시작하며 learnable parameter를 언급한 이유가 바로 이 pooling layer 때문이다.
Pooling layer는 단순히 정해진 규칙의 연산만을 수행하므로 learnable parameter가 없다.
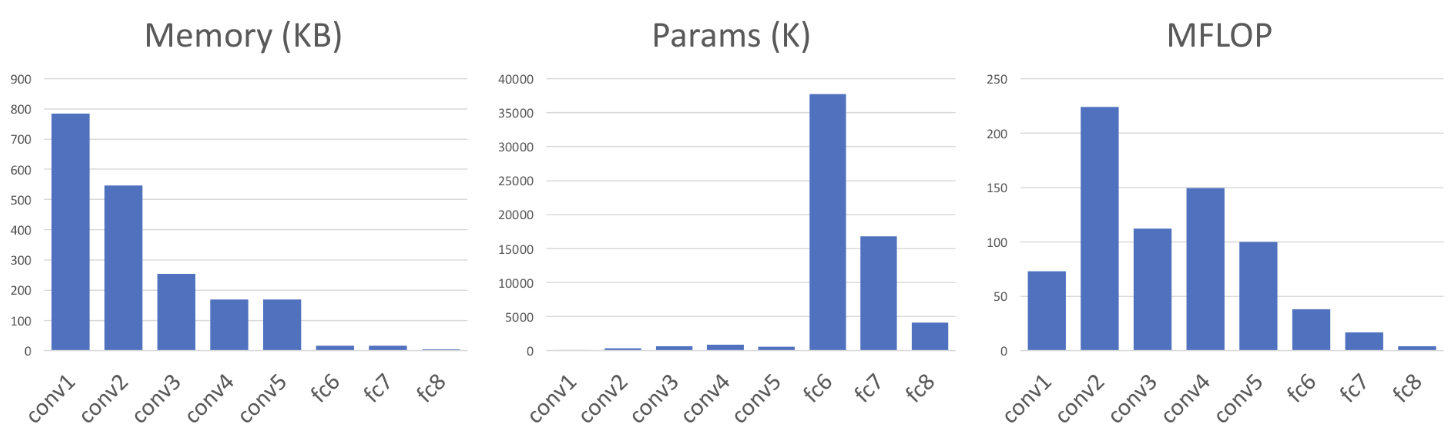
FC layer는 이전 노드와 다음 노드가 모두 완전 연결되어야 하기 때문에 파라미터 개수가 매우 큰 반면, convolution layer는 커널이라는 비교적 작은 파라미터 덩어리를 사용하는 데다가 parameter sharing까지 가능해서 파라미터 개수 측면에서 이점이 있다.
또한 FLOPs 역시 convolution layer가 우세하기 때문에 연산 효율성도 좋다고 할 수 있다.
이러한 장점은 AlexNet에서 model complexity를 늘릴 수 있었던 주된 요소였다.
또한 피규어에는 표현되지 않았으나 FC layer 3번 이후에는 Softmax 모듈이 붙는다.
CNN을 통해 최종적으로 input data가 어떤 클래스에 위치하는지 분류해야 하므로, 특정 클래스에 포함될 확률을 원소로 하는 확률 벡터가 필요하기 때문이다.
논문에서 사용한 데이터셋은 1000개의 클래스를 갖기 때문에 1000-way softmax를 사용했다.
2-2-3. Overfitting prevention: Dropout + Data Augmentation + Overlapping Pooling
- Dropout
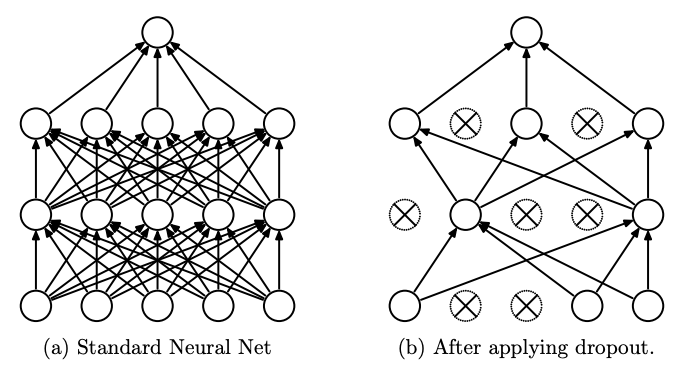
이 역시 개념만 간단히 짚고 넘어가자. 자세한 내용은 Dropout 논문과 Inverted Dropout 기법을 보는 것을 추천한다.
Dropout은 쉽게 생각하면 training stage의 forward pass에서 뉴런을 랜덤 확률 $p$(일반적으로 0.5 사용)로 꺼버리는 기법이다.
Training step을 돌 때마다 랜덤한 구조가 된다는 점에서 각 뉴런이 서로 다른 여러 표현을 할 수 있게 되고, 결국 ensemble learning과 유사한 효과를 낼 수 있게 된다.
결과적으로 overfitting을 예방하는 데에 도움이 되는 것이다.
- Data Augmentation

이 접근법에는 위와 같이 정말 여러 방법이 있지만, AlexNet에서는 이미지 수평 반전과 PCA-based color transformation을 적용했다.
사실 AlexNet이 구체적으로 무슨 테크닉을 적용했는지보다는 이 접근법 자체의 개념이 중요하다.
Data augmentation의 효과로 training data 개수가 증가(이때 augmented data에 대해서 원본과 같은 label을 유지하도록 해야 한다는 점에 유의해야 한다)하게 되며, model complexity를 유지하면서도 data 측면의 overfitting은 감소시키게 된다.
이는 곧 generalization 성능 향상으로 이어짐을 의미한다.
게다가 training 도중이 아닌, 미리 처리하는 방식이라서 training 측면의 추가적인 computational cost 이슈도 없다.
- Overlapping Pooling

Pooling은 데이터를 압축하기 위한 기법으로, average pooling, max pooling 등이 있다.
AlexNet에서는 kernel의 max 값을 선택하는 max pooling을 적용했으며, stride를 적절히 조절하여 위의 예시와는 달리 pooling 영역이 겹치는 overlapping pooling을 적용했다.
논문에서는 위의 예시 이미지처럼 kernel size, stride를 각각 2로 설정했을 때보다 kernel size, stride를 3, 2로 설정해서 overlap을 만들었을 때, 약간의 overfitting prevention 효과가 있었다고 한다.
3. Analysis
3-1. 실험 세팅 요약
3-1-1. 데이터셋
저자들은 ImageNet을 직접 사용하지는 않았고, 그 subset인 ILSVRC 데이터셋 2종류를 사용했다.
- ILSVRC-2010: 메인 실험 데이터셋으로 사용했으며, train 1.2m / val 50k / test 150k
- ILSVRC-2012: 대회 데이터셋으로, 최종 성능 검증에 이용함
3-1-2. 비교 대상
당시 SOTA였던 Sparse coding 모델과 SIFT + FVs 모델을 대조군으로 설정했다.
3-1-3. 평가 지표
메인으로 사용한 것은 Top-1/Top-5 error rate였다.
Top-1은 모델이 내놓은 가장 높은 확률의 prediction 결과가 오답인 비율을 나타낸다.
Top-5는 상위 5개 후보 중에 정답이 없는 경우의 비율을 나타낸다.
두 지표 모두 값이 작을수록 우수한 것이다.
3-2. 연구의 우수성
3-2-1. SOTA 경신


2010년 대회의 test dataset으로 평가한 결과가 좌측의 Table 1으로, CNN(AlexNet)이 확실히 기존 SOTA 모델들에 비해 확연히 낮은 error rate를 보여준다.
또한 우측의 2012년 대회 결과를 보면, CNN 모델 7개로부터 나온 predictions를 averaging하는 ensemble approach로 대회에서 기존 SOTA 모델을 압도했음을 볼 수 있다.
이는 전통적인 CV알고리즘/ML 접근법의 시대가 저물고 DL 시대가 시작되었음을 시사하는 사건이었다.
3-2-2. Depth의 실효성 입증
이렇다 할 Table/Figure는 제시하지 않았지만 논문에서는 depth와 관련한 ablation study에 대해 짧게 언급한다.
저자들은 중간에 위치한 convolution layer를 1개만 제거했을 때도 Top-1이 약 2%나 상승함을 관찰했다.
즉 복잡한 시각 정보를 처리하려면 hierarchical feature extraction을 위한 충분히 깊은 depth가 필수임을 실험적으로 증명한 것이다.
3-2-3. 모델이 학습한 지식

먼저 좌측 피규어를 보면 상위 5개의 labels는 대체로 꽤나 합리적인 후보들로 구성되어 있다.
물론 Madagascar cat처럼 완전 틀리는(Top-5 error) 경우도 존재한다.
특이한 점은 mite처럼 메인 오브젝트가 중심에 없어도 잘 맞출 수 있다는 점이다.
또한 grille, cherry 같은 케이스는 사진이 어디에 의미적 초점을 두는지가 굉장히 모호하다는 점 때문에 잘 맞추지 못한 것으로 보인다.
우측 피규어는 1번 컬럼에 test 이미지가, 2~7번 컬럼에는 각 test 이미지와 유사한 train 이미지들이다.
이는 4096d hidden layer 상에서 test-train 이미지들의 Euclidean distance를 측정했을 때 가까운 것들이다.
Pixel-level에서는 굉장히 다름에도 semantic-level에서는 유사하다고 판단하여 가깝게 encoding을 한 것이다.
즉 AlexNet이 본질적인 의미를 학습했음을 보여준다고 할 수 있다.
4. Novelty
- 혁신적인 아키텍처
이때만 해도 레이어를 여러 층 쌓는다는 것은 어려운 일이었기에, 8-layer NN은 꽤나 deep한 네트워크였을 것이다.
또한 ReLU를 그 정도 규모의 CNN에 적용한 첫 성공 사례로, 학습 속도를 비약적으로 향상시켰다.
- 효과적인 regularization 조합
당시 기준으로 SOTA였던 Dropout과 Data Augmentation, Overlapping Pooling을 적절히 조합해서 대형 모델의 고질적 문제였던 overfitting을 효과적으로 억제할 수 있는 프로토콜을 제시했다.
- GPU parallelism을 통한 연산 최적화
자세히 다룬 내용은 아니지만, 어쨌든 이를 통해 single GPU로 인한 메모리 한계를 극복하고 6000만 가량의 파라미터를 갖는 대형 모델을 5~6일이라는 현실적인 시간 안에 학습할 수 있도록 했다.
5. Discussion & Insight
이 논문은 딥러닝 개론 같은 수업을 들으면 늘 소개되는 근본 논문이라고 볼 수 있다.
나도 관련 수업을 보며 요약본을 여러 번 보긴 했지만, AI 스터디의 첫 리뷰 대상으로 AlexNet을 고르게 되어 처음으로 풀페이퍼를 읽어보게 됐다.
딥러닝 수업을 적지 않게 들어서 핵심내용은 지겨울 정도로 많이 봤지만서도, 직접 읽어보니 디테일은 사뭇 새롭게 느껴졌던 것 같다.
그렇지만 사실 10년도 더 된 논문이고 AI가 아직 봄을 맞이하기 전이었던지라, LRN이라든가, cuda-convnet이라든가, 여러모로 올드한 기술들이 많이 나오기 때문에 그런 부분이 과연 도움이 될까 하는 의문은 남는다.
물론 알아두면 언젠가 도움이 될 날이 있을지도 모르지만 내 입장에서는 꽤나 비효율적인 접근이기에 과감히 생략했다.
한편 같이 공부하는 스터디원들은 AI 도메인 입문자들인 만큼 논문에서 직접적으로 소개하는 내용이 아니더라도 좀 더 기초적인 내용을 섞어서 리뷰를 작성했다.
스터디의 성숙도가 올라가고 리뷰 포스트가 쌓이면 이 정도의 친절함은 사라지지 않을까 싶다.
아마 길이도 좀 더 짧아질 것이고..?
아무튼 있을 때 누리시길..
Note:
부족하거나 잘못된 설명에 대한 피드백은 언제든 환영한다.
또한 궁금한 점이나 새로 얻은 insight를 자유롭게 공유하고 토론했으면 한다.
'AI · 컴퓨터 이론 > Computer Vision' 카테고리의 다른 글
| 논문 리뷰 | Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks (CVPR 2017) (0) | 2026.04.02 |
|---|---|
| 논문 리뷰 | Multi-Task Self-Supervised Visual Learning (ICCV 2017) (0) | 2026.03.31 |